

The Wake-Up Name We All Felt
On October 20, 2025, organizations throughout industries, from banking to streaming, logistics to healthcare, skilled widespread service degradation when AWS’s US-EAST-1 area suffered a major outage. Because the ThousandEyes evaluation revealed, the disruption stemmed from failures inside AWS’s inner networking and DNS decision methods that rippled by means of dependent providers worldwide.
The foundation trigger, a latent race situation in DynamoDB’s DNS administration system, triggered cascading failures all through interconnected cloud providers. However right here’s what separated groups that would reply successfully from these flying blind: actionable, multilayer visibility.
When the outage started at 6:49 a.m. UTC, subtle monitoring instantly revealed 292 affected interfaces throughout Amazon’s community, pinpointing Ashburn, Virginia because the epicenter. Extra critically, as situations developed, from preliminary packet loss to application-layer timeouts to HTTP 503 errors, complete visibility distinguished between community points and utility issues. Whereas floor metrics confirmed packet loss clearing by 7:55 a.m. UTC, deeper visibility revealed a unique story: edge methods have been alive however overwhelmed. ThousandEyes brokers throughout 40 vantage factors confirmed 480 Slack servers affected with timeouts and 5XX codes, but packet loss and latency remained regular, proving this was an utility concern, not a community downside.
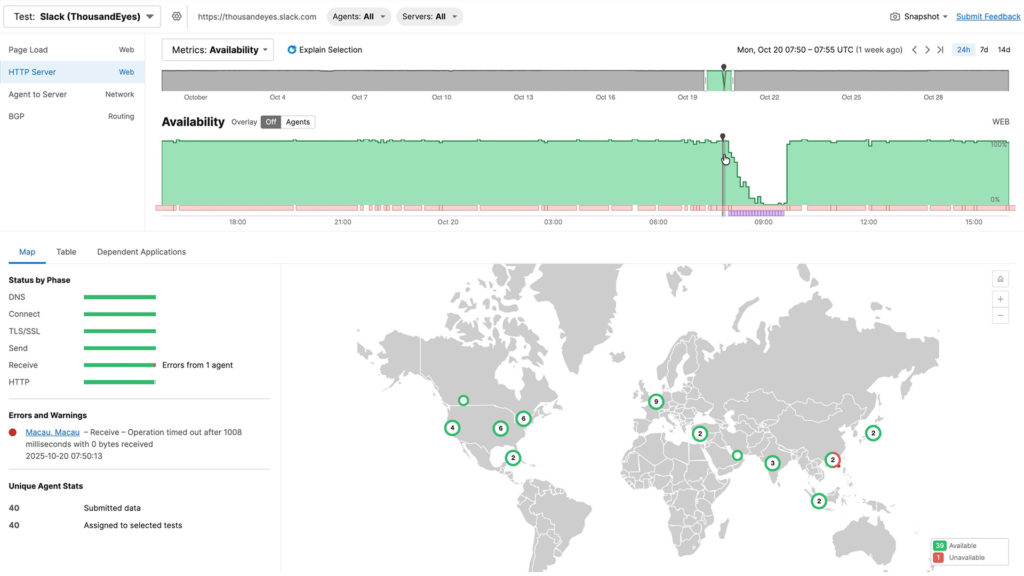
Determine 1. Altering nature of signs impacting app.slack.com in the course of the AWS outage
Endpoint knowledge revealed app.slack.com expertise scores of simply 45% with 13-second redirects, whereas native community high quality remained excellent at 100%. With out this multilayer perception, groups would waste valuable incident time investigating the improper layer of the stack.
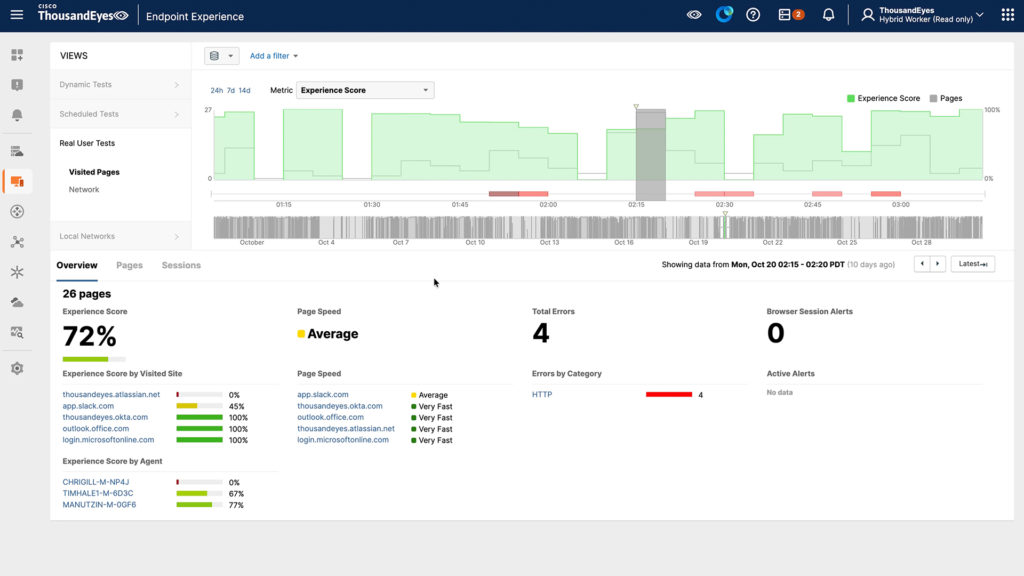
Determine 2. app.slack.com noticed for an finish consumer
The restoration part highlighted why complete visibility issues past preliminary detection. Even after AWS restored DNS performance round 9:05 a.m. UTC, the outage continued for hours as cascading failures rippled by means of dependent methods, EC2 couldn’t keep state, inflicting new server launches to fail for 11 further hours, whereas providers like Redshift waited to recuperate and clear large backlogs.
Understanding this cascading sample prevented groups from repeatedly trying the identical fixes, as an alternative recognizing they have been in a restoration part the place every dependent system wanted time to stabilize. This outage demonstrated three essential classes: single factors of failure conceal in even essentially the most redundant architectures (DNS, BGP), preliminary issues create long-tail impacts that persist after the primary repair, and most significantly, multilayer visibility is nonnegotiable.
In in the present day’s warfare rooms, the query isn’t whether or not you’ve gotten monitoring, it’s whether or not your visibility is complete sufficient to rapidly reply the place the issue is happening (community, utility, or endpoint), what the scope of impression is, why it’s occurring (root trigger vs. signs), and whether or not situations are enhancing or degrading. Floor-level monitoring tells you one thing is improper. Solely deep, actionable visibility tells you what to do about it.
The occasion was a stark reminder of how interconnected and interdependent trendy digital ecosystems have grow to be. Purposes in the present day are powered by a dense net of microservices, APIs, databases, and management planes, lots of which run atop the identical cloud infrastructure. What seems as a single service outage usually masks a much more intricate failure of interdependent elements, revealing how invisible dependencies can rapidly flip native disruptions into world impression.
Seeing What Issues: Assurance because the New Belief Cloth
At Cisco, we view Assurance because the connective tissue of digital resilience, working in live performance with Observability and Safety to offer organizations the perception, context, and confidence to function at machine velocity. Assurance transforms knowledge into understanding, bridging what’s noticed with what’s trusted throughout each area, owned and unowned. This “belief cloth” connects networks, clouds, and functions right into a coherent image of well being, efficiency, and interdependency.
Visibility alone is not adequate. Right this moment’s distributed architectures generate a large quantity of telemetry, community knowledge, logs, traces, and occasions, however with out correlation and context, that knowledge provides noise as an alternative of readability. Assurance is what interprets complexity into confidence by connecting each sign throughout layers right into a single operational reality.
Throughout incidents just like the October 20th outage, platforms comparable to Cisco ThousandEyes play a pivotal position by offering real-time, exterior visibility into how cloud providers are behaving and the way customers are affected. As an alternative of ready for standing updates or piecing collectively logs, organizations can immediately observe the place failures happen and what their real-world impression is.
Key capabilities that allow this embrace:
- International vantage level monitoring: Cisco ThousandEyes detects efficiency and reachability points from the skin in, revealing whether or not degradation stems out of your community, your supplier, or someplace in between.
- Community path visualization: It pinpoints the place packets drop, the place latency spikes, and whether or not routing anomalies originate in transit or throughout the cloud supplier’s boundary.
- Utility-layer synthetics: By testing APIs, SaaS functions, and DNS endpoints, groups can quantify consumer impression even when core methods seem “up.”
- Cloud dependency and topology mapping: Cisco ThousandEyes exposes the hidden service relationships that always go unnoticed till they fail.
- Historic replay and forensics: After the occasion, groups can analyze precisely when, the place, and the way degradation unfolded, reworking chaos into actionable perception for structure and course of enhancements.
When built-in throughout networking, observability, and AI operations, Assurance turns into an orchestration layer. It permits groups to mannequin interdependencies, validate automations, and coordinate remediation throughout a number of domains, from the info middle to the cloud edge.
Collectively, these capabilities flip visibility into confidence, serving to organizations isolate root causes, talk clearly, and restore service sooner.
How one can Put together for the Subsequent “Inevitable” Outage
If the previous few years have proven something, it’s that large-scale cloud disruptions should not uncommon; they’re an operational certainty. The distinction between chaos and management lies in preparation, and in having the appropriate visibility and administration basis earlier than disaster strikes.
Listed below are a number of sensible steps each enterprise can take now:
- Map each dependency, particularly the hidden ones.
Catalogue not solely your direct cloud providers but in addition the management airplane methods (DNS, IAM, container registries, monitoring APIs) they depend on. This helps expose “shared fates” throughout workloads that seem unbiased. - Check your failover logic beneath stress.
Tabletop and dwell simulation workout routines usually reveal that failovers don’t behave as cleanly as supposed. Validate synchronization, session persistence, and DNS propagation in managed situations earlier than actual crises hit. - Instrument from the skin in.
Inside telemetry and supplier dashboards inform solely a part of the story. Exterior, internet-scale monitoring ensures you know the way your providers seem to actual customers throughout geographies and ISPs. - Design for swish degradation, not perfection.
True resilience is about sustaining partial service somewhat than going darkish. Construct functions that may briefly shed non-critical options whereas preserving core transactions. - Combine assurance into incident responses.
Make exterior visibility platforms a part of your playbook from the primary alert to closing restoration validation. This eliminates guesswork and accelerates government communication throughout crises. - Revisit your governance and funding assumptions.
Use incidents like this one to quantify your publicity: what number of workloads depend upon a single supplier area? What’s the potential income impression of a disruption? Then use these findings to tell spending on assurance, observability, and redundancy.
The aim isn’t to eradicate complexity; it’s to simplify it. Assurance platforms assist groups constantly validate architectures, monitor dynamic dependencies, and make assured, data-driven selections amid uncertainty.
Resilience at Machine Pace
The AWS outage underscored that our digital world now operates at machine velocity, however belief should preserve tempo. With out the power to validate what’s actually occurring throughout clouds and networks, automation can act blindly, worsening the impression of an already fragile occasion.
That’s why the Cisco method to Assurance as a belief cloth pairs machine velocity with machine belief, empowering organizations to detect, resolve, and act with confidence. By making complexity observable and actionable, Assurance permits groups to automate safely, recuperate intelligently, and adapt constantly.
Outages will proceed to occur. However with the appropriate visibility, intelligence, and assurance capabilities in place, their penalties don’t must outline your corporation.
Let’s construct digital operations that aren’t solely quick, however trusted, clear, and prepared for no matter comes subsequent.
{kind=link}